S2.02 : Exploration algorithmique d’un problème
Informations préalables
Enseignements ressources :
- R2.01 Dev. objets
- R2.07 Graphes
- R2.09 Méthodes numériques
- R2.02 Dev. d’apps avec IHM
- R2.03 Qualité de dev.
Évaluation
Ce projet est à réaliser en binômes (tirés au sort). L’évaluation portera sur les éléments suivants :
- Livrable 1 (2 points) : une archive
.jarexécutable de votre projet - Livrable 2 (2 points) : le code source, bien structuré
- Livrable 3 (2 points) : javadoc et utilisation de tests unitaires (ces derniers peuvent utiliser notamment la génération automatique de graphes en forme de grilles, comme présenté en section 10 ci-dessous)
- Quiz final individuel lundi 5 juin à 16h10 (14 points)
Important à comprendre : la majorité de votre note proviendra du quiz individuel. Ce dernier vous semblera facile si vous avez réalisé vous-même et bien compris toutes les étapes du projet. Plusieurs quiz intermédiaires sont disponibles dans cette page pour vous permettre de vous auto-évaluer au fur et à mesure. Ces derniers ne sont pas notés. Nous vous conseillons de les réaliser individuellement même lorsque vous serez en binôme.
Indiquez les noms du binôme dans le titre de la fenêtre. L’ensemble des fichiers à rendre peut être déposée comme une archive unique avant le SAMEDI 3 JUIN à MINUIT sur Moodle (clé d’inscription “R2.07”, si vous n’êtes pas déjà inscrit). Cette archive contiendra : un JAR exécutable (*); un répertoire contenant la javadoc (générée à partir de votre code); et un répertoire contenant le code source (et les tests). Un seul dépôt par binôme (ou monôme, si vous êtes seul) est suffisant, en indiquant vos noms de famille dans le nom de l’archive.
(*) Concernant le JAR exécutable : si vous n’arrivez pas à inclure la dépendance à JBotSim directement dans votre JAR, nous acceptons aussi les configurations dans lesquelles votre JAR fonctionne lorsque JBotSim est présent dans le “classpath”. À toutes fins utiles, JBotSim peut être récupéré sous forme d’un JAR ici.
Aperçu du projet
Le projet consiste à développer une application pour le calcul d’itinéraires, en Java (IDE de votre choix).
Dans cette application, l’utilisateur choisit un point de départ (source, sommet noir sur la Figure 1) et un point d’arrivée (destination, drapeau rouge sur la Figure 1).

Figure 1. Choix d'une source et d'une destination.
Un algorithme est ensuite exécuté pour calculer les plus courts chemins de la source vers tous les autres sommets. Plusieurs algorithmes et variantes du problème seront considérés.

Figure 2. Calcul des chemins de la source vers tous les sommets.
Enfin, le chemin allant de la source à la destination est sélectionné et affiché à l’utilisateur.

Figure 3. Affichage du chemin de la source à la destination.
Lien avec les enseignements ressources :
- Algorithmes de calcul de chemins (R2.07 - Graphes)
- Analyse de complexité algorithmique (R2.09 - Méthodes numériques)
- Réalisation d’une interface utilisateur (R2.02 - Dev. d’apps avec IHM)
- Tout cela se fait en Java (R2.01 - Dev. objets)
- Réalisation d’une javadoc et de tests unitaires (R2.03 - Qualité de dev.)
Vous serez guidés dans la réalisation de ce projet par un certain nombre d’instructions et de quiz intermédiaires (non évalués) vous permettant de vérifier que vous êtes prêts à poursuivre.
C’est parti !
1) Création d’un projet minimaliste
Pour manipuler et représenter nos graphes, nous allons utiliser la bibliothèque JBotSim.
→ Travail à faire (1.1) : Suivre la page HelloWorld du tutoriel de JBotSim (cette page là seulement). Cela vous expliquera comment créer un projet, ajouter la dépendance à la bibliothèque JBotSim et créer un exemple minimal. Notez que le tutoriel explique comment faire cela avec IntelliJ. Si vous préférez utiliser Netbeans (par exemple), une fois votre projet créé, allez dans l’arborescence du projet, dossier “Dependencies”, faites click droit, “Add Dependency”, puis entrez les informations suivantes :
- Group ID : io.jbotsim
- Artifact ID : jbotsim-all
- Version : 1.2.0
Objectif : Vous devez obtenir un rendu similaire à celui de la Figure 4.

Figure 4. Exemple de graphe obtenu en cliquant à la souris.
Remarque : Par défaut, les arêtes sont ajoutées automatiquement en fonction de la distance entre les nœuds. Il est possible de changer ce comportement pour créer des graphes différents, mais ce n’est pas nécessaire dans ce projet.
→ QUIZ de la section 1
2) Gestion des composants graphiques
Dans l’exemple précédent, l’objet JViewer gère lui-même le fenêtrage et les composants graphiques permettant de dessiner le graphe. Bien que pratique, cela donne peu de souplesse. Nous allons donc créer une autre application, dont nous gérerons nous-mêmes les composants et à laquelle nous ajouterons des boutons. La classe ci-dessous donne un exemple de code permettant de faire cela. La bibliothèque de composants utilisée est swing (intégrée à Java).
import io.jbotsim.core.Topology;
import io.jbotsim.ui.JTopology;
import javax.swing.*;
import java.awt.BorderLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
public class MonApplication implements ActionListener {
Topology tp; // Objet qui contient le graphe
JTopology jtp; // Composant graphique qui affiche le graphe
public MonApplication() {
// Création du graphe
tp = new Topology();
// Création de l'interface graphique (ci-dessous)
creerInterfaceGraphique();
}
private void creerInterfaceGraphique() {
// Création d'une fenêtre
JFrame window = new JFrame("Mon application");
window.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
// Création du composant graphique qui affiche le graphe
jtp = new JTopology(tp);
window.add(jtp);
// Création d'un bouton test
JButton button = new JButton("Test");
window.add(button,BorderLayout.NORTH);
// Abonnement aux évènements du bouton (clic, etc.)
button.addActionListener(this);
// Finalisation
window.pack();
window.setVisible(true);
}
@Override
public void actionPerformed(ActionEvent e) {
if (e.getActionCommand().equals("Test")) {
JOptionPane.showMessageDialog(null, "Bouton cliqué");
}
}
public static void main(String[] args) {
new MonApplication();
}
}
→ Travail à faire (2.1) : Copier ce code dans une classe MonApplication, l’exécuter et tenter de comprendre toutes les instructions.
Vous devriez obtenir un rendu similaire à celui de la Figure 5 (lorsque le bouton est cliqué).

Figure 5. Exemple d'application qui gère elle-même ses composants.
→ Travail à faire (2.2) : Ajouter un second bouton en bas de la fenêtre. Lorsqu’un bouton est cliqué, affichez un message différent selon le bouton qui a été utilisé.
→ QUIZ de la section 2
3) Sélection des sommets source et destination
→ Travail à faire (3.1) : Créer deux variables de type Node dans votre classe, que vous appellerez source et destination. Ces variables représenteront les sommets choisis par l’utilisateur. Vous pouvez les initialiser à null.
On souhaite permettre à l’utilisateur de choisir ces sommets à la souris. JBotSim permet de sélectionner des sommets en cliquant dessus avec le bouton de la molette (ou bien ctrl+clic gauche si vous n’avez pas de molette). Pour récupérer cet évènement, il faut que votre classe implémente l’interface SelectionListener, qu’elle possède la méthode correspondante : public void onSelection(Node selectedNode){}, et que vous souscriviez à cet évènement auprès de la topologie, en appelant .addSelectionListener(this) à un endroit approprié.
→ Travail à faire (3.2) : Ajouter SelectionListener à la liste des interfaces que votre classe implémente, ajouter la méthode correspondante et souscrivez aux évènements (notez que cela fait trois choses à faire).
Difficultés potentielles : Selon l’IDE que vous utilisez, la méthode pourrait être automatiquement générée après avoir ajouté l’interface SelectionListener. Si ce n’est pas le cas, voici le code correspondant.
@Override
public void onSelection(Node selectedNode) {
}
ainsi que les imports correspondants :
import io.jbotsim.core.Node;
import io.jbotsim.core.event.SelectionListener;
→ Travail à faire (3.3) : Implémenter le comportement suivant dans la méthode onSelection. Si la variable source vaut null, lui affecter le sommet que l’utilisateur vient de sélectionner (passé en paramètre); sinon, si la variable destination vaut null, lui affecter le sommet sélectionné. Si aucun des deux n’est null, ne rien faire.
→ Travail à faire (3.4) : Toujours dans onSelection, lorsqu’un sommet est choisi comme source ou comme destination, on peut lui donner une couleur distincte pour le visualiser. Pour cela, on peut procéder comme suit :
source.setColor(Color.black);
Difficultés potentielles : Attention, il existe différentes classes Color. Celle que nous utilisons ici est celle de JBotSim, veillez à ce que l’import utilisé soit bien import io.jbotsim.core.Color et non awt.Color ou awt.*.
→ Travail à faire (3.5) : Faire en sorte que l’un des boutons évoqués plus haut soit utilisé pour réinitialiser la sélection des sommets, en mettant les deux variables correspondantes à null et en enlevant leur couleur via setColor(null). Bien sûr, vous pouvez changer le libellé du bouton.
→ Bonus (facultatif) : Plutôt que d’utiliser une couleur, changer l’icône de la destination en un drapeau rouge. Vous pouvez utiliser pour cela la méthode setIcon et l’une des icônes prédéfinies dans la classe Icons du package io.jbotsim.ui.icons.
Vous devriez obtenir un rendu semblable à celui de la Figure 6 :
Figure 6. Choix d'une source et d'une destination.
Bilan: Nous voici désormais prêts à faire de l’algorithmique ! Avant de continuer, vérifiez que vous maîtrisez bien les concepts que nous avons couverts dans cette section, grâce au quiz.
→ QUIZ de la section 3
4) Parcours en largeur
Le premier algorithme que nous allons implémenter revient à effectuer un parcours en largeur depuis le sommet source. Comme vu en cours, ce parcours définit un arbre couvrant qui a pour racine le sommet source et dans lequel la distance de chaque sommet à la racine est identique à ce qu’elle est dans le graphe d’origine (on considère ici comme longueur d’un chemin le nombre d’arêtes qu’il utilise). Le plus court chemin entre la source et la destination sera donc l’unique chemin qui les relie dans cet arbre.
Préparation du code
→ Travail à faire (4.1) : Créer une méthode ParcoursEnLargeur qui prend deux paramètres : l’un de type Topology (le graphe) et l’autre de type Node (le sommet source choisi par l’utilisateur).
Le type de retour de cette méthode doit être une structure de données qui permette d’associer à chaque sommet (de type Node) son sommet parent dans l’arbre (de type Node également).
→ Travail à faire (4.2) : Trouver la structure de données appropriée pour faire cela en Java. Si l’occasion s’y prête, faire valider ce choix par l’enseignant. Puis créer cette structure de données au début de la méthode, en initialisant les parents de tous les sommets à null, sauf le parent de la source, qui par convention sera la source elle-même.
Aide sur l’API : Vous pouvez récupérer la liste des sommets en appelant la méthode getNodes() sur la topologie. Par ailleurs, en Java, on peut parcourir tous les éléments d’une collection (liste ou autre) de façon très simple, en utilisant le mot clé : (cherchez sur internet comme faire, si besoin).
L’algorithme
Pour rappel, voici une version de l’algorithme de parcours en largeur, utilisant une file d’attente pour visiter les sommets découverts. Attention : cet algorithme est donné en pseudo-code, avec plusieurs différences importantes avec Java.
f = CréerFile()
f.enfiler(source)
Tant Que f est non vide, Faire
s = f.défiler() // supprime également l'élément
pour tout voisin v de s, Faire
si parent[v] == null, Alors
parent[v] ← s
f.enfiler(v)
→ Travail à faire (4.3) : Faire tourner cet algorithme à la main sur l’exemple de la Figure 7, en prenant pour source le sommet C et en notant sur un brouillon l’évolution du contenu de la file. Si vous êtes en classe avec un enseignant, montrez-lui l’arbre couvrant qui en résulte (lorsqu’il y a plusieurs choix de voisins, prenez-les dans un ordre quelconque).
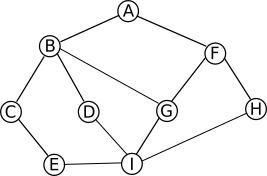
Figure 7. Exemple de graphe.
Implémentation
→ Travail à faire (4.4) : Chercher les réponses aux questions suivantes :
- Comment manipuler une file d’attente en Java ? (attention, en anglais une file se dit “queue” et un fichier se dit “file”…)
- Quels appels de méthodes remplaceront la syntaxe de parent[v] ← s dans le pseudo-code de l’algorithme, en considérant la structure de données que vous avez choisie pour mémoriser les parents ? Et en lecture ?
- Quelles méthodes permettent d’enfiler et de défiler un élément ? Vous avez plusieurs choix, ils sont tous bons.
- En Java,
Queueest une interface, mais ce n’est pas une classe. Un exemple de classe qui implémente cette interface estLinkedList. Peut-on déclarer notre file de sorte à restreindre l’utilisation des méthodes aux seules méthodes de l’interfaceQueue, sans permettre l’accès aux autres méthodes de la classeLinkedList? - Comment récupérer la liste des voisins d’un sommet dans JBotSim ? (Indice 1 : c’est une méthode de la classe
Node, dont la javadoc est disponible ici – Indice 2 : notre graphe est bien non-orienté (undirected))
→ Travail à faire (4.5) : Implémenter l’algorithme !
Astuce de visualisation : Pour indiquer qu’une arête entre deux sommets, disons s1 et s2, fait partie de l’arbre, on peut changer son épaisseur en écrivant par exemple s1.getCommonLinkWith(s2).setWidth(4); (le paramètre d’épaisseur est le nombre de pixels, par défaut 1).
Vous devriez obtenir un résultat semblable à celui de la Figure 8.
Figure 8. Arbre des plus courts chemins de la source vers tous les sommets.
Remarque : Pour optimiser un peu le calcul, il est possible d’arrêter la construction de l’arbre dès que la destination a été trouvée.
→ Travail à faire (4.6) : Mettez à jour votre méthode de réinitialisation pour supprimer le dessin de l’arbre ! Vous pouvez récupérer la liste des arêtes (de type Link) en appelant getLinks() sur la topologie.
→ QUIZ de la section 4
5) Récupérer le chemin à partir de l’arbre
Nous avons désormais en notre possession un arbre, encodé par une structure qui associe à chaque sommet son parent. Il nous reste donc à extraire de cet arbre le chemin qui nous intéresse entre la source et la destination. Cette partie est laissée plus libre.
→ Travail à faire (4.5) : Écrire une méthode extraireChemin qui prend en entrée la source, la destination, ainsi que la structure qui représente les liens de parenté. Votre méthode doit renvoyer une liste de sommets à parcourir de la source à la destination, qui correspond au plus court chemin.
Difficulté potentielle : Il est possible que vous récupériez ces sommets dans l’ordre inverse du chemin. Il faudra donc l’inverser, ou bien gérer la récupération de façon plus subtile.
→ Travail à faire (4.6) : Faire en sorte de n’afficher que les arêtes du chemin en gras, et d’afficher la liste des sommets à l’utilisateur (sur la sortie standard ou dans une boite de dialogue). L’identifiant de chaque sommet est unique et correspond à un nombre entre 0 et n-1, on peut le voir en passant la souris sur le sommet, et on peut le récupérer en utilisant node.getID().
Vous devriez obtenir un rendu similaire à celui de la Figure 9.
Figure 9. Affichage du chemin de la source à la destination.
→ QUIZ de la section 5
6) Une variante plus intéressante
À partir de cette section, la façon dont vous gérez vos interactions avec l’utilisateur et votre interface graphique sont laissées libres, faites comme vous voulez.
→ Travail à faire (4.7) : Permettre à l’utilisateur d’indiquer des sommets à éviter. Vous pouvez les représenter par une couleur différente (par exemple, rouge). Votre algorithme de parcours devra être adapté pour éviter de passer par ces obstacles-là, comme illustré à la Figure 10.

Figure 10. Recherche de chemin contournant des obstacles.
Pas de quiz pour la section 6
7) Graphes pondérés
Dans les sections qui suivent, nous allons considérer le cas des graphes pondérés. Les graphes que nous créons sous JBotSim sont plongés dans le plan, c’est à dire que chaque sommet a des coordonnées 2D. Il est donc naturel de considérer comme poids pour les arêtes la distance euclidienne entre ses deux sommets extrémités. Dans ce contexte, trouver le plus court chemin entre la source et la destination revient à trouver un chemin dont la somme des poids (c.-à-d. la somme des longueurs d’arêtes) est aussi petite que possible.
Quelques éléments d’API pour plus tard:
- La distance entre deux sommets
v1etv2de typeNode(voisins ou non), peut être obtenue en appelantv1.distance(v2), qui renvoie undouble. Par défaut, l’unité coïncide avec un pixel dans le rendu graphique. - Ce ne sera peut-être pas nécessaire, mais si besoin, la longueur d’une arête
ade typeLinkpeut être obtenue en appelanta.getLength().
Pas de quiz pour la section 7
8) Algorithme A*
Le parcours en largeur vu plus haut, de même que l’algorithme de Dijkstra (que nous n’implémenterons pas), reposent tous deux sur la construction d’un arbre dont la source est la racine, et dans lequel les distances entre la source et chaque autre sommet sont minimisées (qu’il s’agisse du nombre d’arêtes, pour le premier, ou de la somme des poids, pour le second). Le défaut principal de ces algorithmes est que tous les sommets dont la distance à la source est inférieure à celle de la destination seront explorés par l’algorithme. Cela devient coûteux lorsque le graphe est grand. Intuitivement, l’algorithme A* évite ce problème en avançant directement vers la destination, grâce à l’utilisation d’une file prioritaire.
Nouvelle structure de données : la file prioritaire !
Contrairement à une file classique, la file prioritaire ne respecte pas forcément l’ordre d’insertion (elle n’est pas de type FIFO), au contraire, elle permet à des éléments nouvellement insérés de “griller la priorité” à des éléments existants en fonction d’une valeur spécifiée lors de l’insertion (la priorité).
Exemple de fonctionnement :
Supposons que l’on favorise les priorités les plus petites (“min priority queue”), ce qui est le cas en Java. Si l’on insère les éléments suivants : A avec priorité 12, puis B avec priorité 17, puis C avec priorité 4, et enfin D avec priorité 6, ces éléments seront défilés dans l’ordre C, puis D, puis A, et enfin B.
→ Travail à faire (8.1) S’assurer d’avoir bien compris le principe d’une file prioritaire.
Fonctionnement de l’algorithme A*
Le fonctionnement de l’algorithme A* est très similaire à celui d’un parcours en largeur : lorsqu’on explore un sommet, on insère dans la file prioritaire ses voisins qui n’ont pas encore de “parent”. La différence principale est que l’on utilise une file prioritaire plutôt qu’une file classique, afin de donner la priorité aux sommets qui nous semblent les plus prometteurs (plutôt qu’à ceux qui attendent depuis le plus longtemps).
→ Travail à faire (8.2) : Trouver un critère simple qui permette d’estimer qu’un sommet semble plus prometteur qu’un autre pour avancer vers la destination. Pour rappel : on considère ici un graphe plongé dans le plan (cf. plus haut).
Remarque : On appelle fonction d’estimation la fonction qui estime la qualité d’un élément potentiel à explorer (la valeur correspondant servant de priorité). Bien entendu, les qualités de l’algorithme dépendent en grand partie de la qualité de cette estimation.
→ Travail à faire (8.3) : Réfléchir à la qualité de l’estimation que vous renvoyez dans différents cas de figure. Dans quels cas cette estimation est bonne, et dans quels cas elle pourrait se tromper de façon plus importante ?
→ Question bonus (facultative) : Comment l’algorithme A* se comporte lorsque la fonction d’estimation renvoie toujours la même valeur ? Il pourrait être intéressant de tester cela sur un graphe de taille conséquente, afin de comparer le résultat avec l’autre fonction d’estimation. Par ailleurs, existe-t-il une fonction d’estimation qui permet de simuler un parcours en largeur ?
→ QUIZ de la section 8
9) Implémentation reposant sur A*
Voici le pseudo-code correspondant à la version A* de notre algorithme.
f = CréerFilePrioritaire()
f.enfiler(source)
Tant Que f est non vide, Faire
s = f.défiler() // supprime également l'élément
pour tout voisin v de s, Faire
si parent[v] == null, Alors
parent[v] ← s
priorité ← estimerQualité(v)
f.enfiler(v, priorité)
Attention : L’utilisation d’une file prioritaire en Java comporte des différences importantes avec ce code, qui feront l’objet de questions dédiées. Mais conceptuellement, ce code correspond bien à ce que nous allons faire.
Files prioritaires en Java
→ Travail à faire (9.1) Trouver la classe Java standard qui correspond à une file prioritaire (elle existe !).
La classe que vous avez trouvée permet bien d’utiliser des priorités. Cependant, la façon de spécifier la priorité d’un élément est différente du pseudo-code ci-dessus. Plutôt que de la donner explicitement lors de l’insertion, l’ordre est automatiquement déterminé par la file, en comparant l’élément inséré avec les éléments présents via un comparateur.
→ Travail à faire (9.2) Faire en sorte que l’une de vos classes implémente l’interface Comparator<Node> et créer la méthode compare() correspondante.
Le but de cette méthode est de comparer deux éléments passés en paramètres. Cette méthode sera appelée autant de fois que nécessaire lors d’une insertion, pour placer correctement le nouvel élément dans la file. Ces appels seront faits automatiquement, nous n’avons pas à nous en soucier, par contre nous devons bien fournir la méthode qui compare.
→ Travail à faire (9.3) Faire en sorte que cette méthode compare les deux sommets passés en paramètre, en se basant sur le critère choisi à la question 8.2. La valeur de retour doit respecter la spécification officielle.
→ Travail à faire (9.4) Implémenter l’algorithme complet ! (Spoiler alert: tout est presque déjà fait…) Attention, il faut stopper l’algorithme une fois la destination atteinte, sinon l’algorithme explorera tout le graphe.
Vous devriez obtenir un rendu similaire à celui des figures suivantes :


Figure 10. Recherche de chemin utilisant A*, sans obstacle (à gauche) ou avec obstacles (à droite).
Ces figures représentent les sommets explorés par l’algorithme au fur et à mesure et non le chemin final (même si les deux coïncident complètement dans l’exemple de gauche, et quasiment dans celui de droite). On peut vérifier qu’à chaque étape, l’algorithme choisit bien le sommet qui le rapproche le plus de la destination. Dans le cas de la figure de droite, on voit qu’une tentative a été effectuée sur un sommet qui s’est avéré être une impasse. C’est normal, l’estimation que nous utilisons pour la priorité n’anticipe pas les obstacles (ou les endroits vides). Mais globalement, on peut constater que la grande majorité du graphe n’a pas eu besoin d’être explorée, c’est la qualité principale de l’algorithme A*.
→ QUIZ de la section 9
10) Génération de graphes
Il n’y a pas de travail à effectuer dans cette section, nous expliquons simplement comment générer des graphes susceptibles de vous être utiles dans les sections suivantes (ou dans vos tests). Pour commencer, voici une méthode permettant de générer automatiquement une grille ayant autant de lignes que de colonnes.
public static void genererGrille(Topology tp, int nbRows){
int stepX = (tp.getWidth() - 100) / (nbRows - 1);
int stepY = (tp.getHeight() - 100) / (nbRows - 1);
if (Math.max(stepX, stepY) >= 2 * Math.min(stepX, stepY)){
String s = "les proportions de la topologie sont inadaptées";
JOptionPane.showMessageDialog(null, s);
return;
}
tp.setCommunicationRange(Math.max(stepX, stepY)+1);
for (int i = 50; i <= tp.getWidth() - 50; i += stepX){
for (int j = 50; j <= tp.getHeight() - 50; j += stepY) {
tp.addNode(i, j, new Node());
}
}
}
Le paramètre nbRows est le nombre de lignes (et de colonnes), par exemple si vous appelez genererGrille(tp, 6), vous obtiendrez un graphe à $n = 36$ sommets représenté comme suit :

Figure 10. Génération d'une grille.
Notez que les arêtes sont créées automatiquement selon la distance entre les noeuds (le seuil est calculé exprès et fixé via setCommunicationRange()). Si vous préférez créer vos propres graphes en spécifiant vous mêmes les arêtes, il suffit de désactiver les arêtes automatiques (tp.disableWireless()) et de créer vos objets de type Node et Link directement, par exemple le code
Node n1 = new Node();
Node n2 = new Node();
tp.addNode(100, 100, n1);
tp.addNode(500, 100, n2);
tp.addLink(new Link(n1, n2));
crée un graphe représenté comme suit :

Figure 11. Génération "manuelle" d'un graphe.
11) Complexité algorithmique
La fin de cette SAÉ s’intéressera à la complexité algorithmique des algorithmes considérés, c’est à dire le nombre d’opérations qu’ils nécessitent en fonction de certaines propriétés du graphe. Les séances auront lieu en salle de classe, avec vos professeurs de mathématique. Ils ne donneront peut-être pas lieu à des développements supplémentaires, mais le contenu de ces cours sera intégré au quiz final.